R for Learner Corpus Research 2020: 09
sugiura
2020/12/25
調べたい表現の頻度
特定の表現を指定したら、その表現を含む行を出力
myGrep <- function(a){
lines.tmp <- scan(choose.files(), what="char", sep="\n")
grep(a, lines.tmp, value=T)
}
実行
myGrep("I think")
ディレクトリー内のすべてのファイル内で特定の表現を検索し、その件数を出力
myGrepFiles <- function(a){
#copyleft
2020-12-18 sugiura@nagoya-u.jp
files <- list.files()
hitV
<- c()
for (j in files) {
hitN <- 0
lines.tmp <- scan(j, what="char", sep="\n")
hit
<- grep(a, lines.tmp)
# 該当する要素番号がhitに入
hitN <- length(hit)
# 該当する要素の数を数える
#
print(hit)
hitV <- c(hitV, hitN)
# ファイルごとの該当する数が並んだベクトル
}
# hitV
# ファイルごとの数の一覧
sum(hitV)
# 総計
}
実行
setwd("NICER1_3/NICER_NNS")
myGrepFiles("I think")
## [1] 1248
setwd("NICER1_3/NICER_NS")
myGrepFiles("I think")
## [1] 24
事前に調べたい複数の表現を決めて、それぞれの頻度を出力する
• 二種類の表現を例に
myGrepExpressions <- function(a,b){
#copyleft
2020-12-19 sugiura@nagoya-u.jp
files <- list.files()
hitV_a
<- c()
hitV_b
<- c()
for (j in files) {
hitN_a <- 0
hitN_b <- 0
lines.tmp <- scan(j, what="char", sep="\n")
hit_a <- grep(a, lines.tmp)
# 該当する要素番号がhitに入
hitN_a <- length(hit_a)
# 該当する要素の数を数える
hit_b <- grep(b, lines.tmp)
# 該当する要素番号がhitに入
hitN_b <- length(hit_b)
# 該当する要素の数を数える
#
print(hit)
hitV_a <- c(hitV_a, hitN_a)
# ファイルごとの該当する数が並んだベクトル
hitV_b <- c(hitV_b, hitN_b)
}
# hitV
# ファイルごとの数の一覧
sum_a <- sum(hitV_a)
# 総計
sum_b <- sum(hitV_b)
cat(sum_a, sum_b, "\n")
}
実行
## 1248 55
複数の表現について、個々のファイルごとの頻度をデータフレームに保存
• 二つの表現を例に
myGrepExpressionsDF <- function(a,b){
#copyleft
2020-12-19 sugiura@nagoya-u.jp
files <- list.files()
hitV_a
<- c()
hitV_b
<- c()
for (j in files) {
hitN_a <- 0
hitN_b <- 0
lines.tmp <- scan(j, what="char", sep="\n")
hit_a <- grep(a, lines.tmp)
# 該当する要素番号がhitに入
hitN_a <- length(hit_a)
# 該当する要素の数を数える
hit_b <- grep(b, lines.tmp)
# 該当する要素番号がhitに入
hitN_b <- length(hit_b)
# 該当する要素の数を数える
#
print(hit)
hitV_a <- c(hitV_a, hitN_a)
# ファイルごとの該当する数が並んだベクトル
hitV_b <- c(hitV_b, hitN_b)
}
data.frame(hitV_a, hitV_b)
# ファイルごとの数の一覧
#sum_a <- sum(hitV_a)
# 総計
#sum_b <- sum(hitV_b)
#cat(sum_a, sum_b, "\n")
}
実行
#setwd("NICER1_3/NICER_NNS")
setwd("NICER1_3/NICER_NS")
exp.df <- myGrepExpressionsDF("I think", "I believe")
names(exp.df) <- c("I_think", "I_believe")
exp.df
## I_think
I_believe
## 1
0
0
## 2
0
0
## 3
0
1
## 4
0
0
## 5
0
0
## 6
0
2
## 7
0
0
## 8
0
0
## 9
2
2
## 10 0
0
## 11 0
0
## 12 0 0
## 13 0
0
## 14 0
2
## 15 0
0
## 16 0
0
## 17 0
0
## 18 0
0
## 19 0
0
## 20 0
1
## 21 0
0
## 22 0
0
## 23 0
0
## 24 1
2
## 25 1
0
## 26 0
0
## 27 0
0
## 28 0
0
## 29 0
0
## 30 0
0
## 31 0
0
## 32 1
3
## 33 1
0
## 34 0
1
## 35 0
0
## 36 0
0
## 37 0
0
## 38 0
0
## 39 3
1
## 40 0
0
## 41 0
0
## 42 0
0
## 43 0
0
## 44 1 2
## 45 0
1
## 46 0
0
## 47 0
0
## 48 0
0
## 49 0
0
## 50 0
0
## 51 6
3
## 52 0
0
## 53 1
1
## 54 1
2
## 55 0
4
## 56 2
4
## 57 3
3
## 58 0
0
## 59 0
0
## 60 0
0
## 61 0
0
## 62 0
1
## 63 0
2
## 64 0
0
## 65 1
0
## 66 0
1
## 67 0
1
## 68 0
1
## 69 0
0
## 70 0
0
## 71 0
0
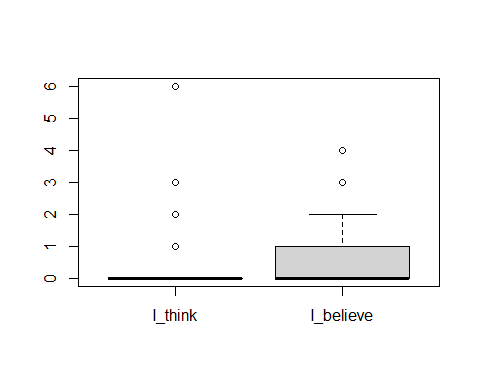
str(exp.df)
## 'data.frame': 71 obs. of 2 variables:
## $ I_think : int 0 0 0 0 0 0 0 0 2 0 ...
## $ I_believe:
int 0 0 1 0 0 2 0 0 2 0 ...
boxplot(exp.df)
コーパス分析専用パッケージの利用
corpus
http://sugiura-ken.org/wiki/wiki.cgi/exp?page=corpus
quanteda: Quantitative Analysis of Textual Data
http://sugiura-ken.org/wiki/wiki.cgi/exp?page=quanteda
quantedaの使用例
パッケージのインストール
qunateda 本体
install.packages("quanteda", dependencies=T, repos="http://cran.rstudio.com/")
library(quanteda)
## Package version: 2.1.2
## Parallel computing: 2 of 12 threads used.
## See https://quanteda.io for tutorials and examples.
##
## Attaching package: 'quanteda'
## The
following object is masked from 'package:utils':
##
## View
テキストファイルをコーパス分析用のデータとして読み込むreadtextパッケージ
install.packages("readtext", dependencies = T, repos="http://cran.rstudio.com/")
library(readtext)
テキストデータの読み込み
•
タグなどのついていない、テキストデータのみのファイルを、フォルダーにまとめて入れておく。
•
NICERの学習者データについて、テキストのみのファイルに変換する
NICERのCHAT形式のデータをテキスト形式に変換:chatToText.R
https://sugiura-ken.org/wiki/wiki.cgi/exp?page=chatToText
#chatToText
#2020-01-17 sugiura@nagoya-u.jp
#CHATフォーマットのファイルから、
#本文のメインティアのテキストだけを抜き出して
#もとのファイル名に
.data を付け足したファイル名で保存する。
chatToText <- function(){
#ディレクトリー内のすべてのテキストファイルを対象に
here <- getwd()
files <- list.files(here, pattern="\\.txt$")
#読み込むファイル名で、.txt という拡張子でファイル名が終わるものを指定
for (i in files){
lines.tmp
<- scan(i, what="char", sep="\n")
lines.tmp
<- scan(i, what="char", sep="\n")
data.tmp
<- grep("\\*(JPN|NS)...:\t", lines.tmp, value=T)
body.tmp
<- gsub("\\*(JPN|NS)...:\t", "", data.tmp)
body.tmp
<- body.tmp[body.tmp !=
""]
filename <- i
filename <- as.factor(filename)
filename <- paste(filename, ".data", sep="")
#もとのファイル名に
.data という文字列を追加
#ファイル名の終わりが .txt
ではなくなるので再帰的に読み込まれない
write(body.tmp, file=filename)
}
}
変換実行
setwd("NICER1_3/NICER_NNS")
chatToText()
•
元データと同じフォルダー内に、拡張子 .data が付いたファイルが生成される。
setwd("NICER1_3/NICER_NNS")
list.files()
•
元のCHAT形式の .txtファイルと、変換後の .data ファイルの二種類が混在している点に注意。
– (.data ファイルだけ別のフォルダーに移動しておくのも手。)
readtextパッケージの readtext() を使ってテキストを読み込む
•
拡張子 .data
が付いたファイルだけを読み込むようにする点に注意。
setwd("NICER1_3/NICER_NNS")
nicerJP.data <- readtext("*.data")
コーパス分析用として読み込まれたデータの確認
nicerJP.data
## readtext object consisting of 381 documents and 0 docvars.
## # Description: df[,2] [381 x 2]
## doc_id
text
## <chr>
<chr>
## 1 JPN501.txt.data
"\"What kind \"..."
## 2 JPN502.txt.data
"\"Education \"..."
## 3 JPN503.txt.data "\"educationa\"..."
## 4 JPN504.txt.data
"\"The impact\"..."
## 5 JPN505.txt.data "\"About
spor\"..."
## 6 JPN506.txt.data
"\"Is money t\"..."
## # ... with 375 more rows
•
doc_id に続いて、本文が text として読み込まれている。
「コーパスデータ化」する: corpus()
nicerJP.corpus <- corpus(nicerJP.data)
nicerJP.corpus
## Corpus
consisting of 381 documents.
## JPN501.txt.data :
## "What kind of sports do
you like? Do you like soccer, base ba..."
##
## JPN502.txt.data :
## "Education of
"YUTORI" There was the education system that ca..."
##
## JPN503.txt.data :
## "educational policy What
do you think about "yutori kyouiku"?..."
##
## JPN504.txt.data :
## "The impact of sports You
often play sports. In elementary sc..."
##
## JPN505.txt.data :
## "About sports I want to
talk about doing sports. To tell you ..."
##
## JPN506.txt.data :
## "Is money the most important
thing? I often hear that which i..."
##
## [ reached max_ndoc
... 375 more documents ]
コーパスデータの概要を見る: summary()
summary(nicerJP.corpus)
## Corpus
consisting of 381 documents, showing 100 documents:
##
##
Text Types Tokens Sentences
## JPN501.txt.data 153 391 29
## JPN502.txt.data 171 411 27
## JPN503.txt.data 130 223 12
## JPN504.txt.data 149 306 26
## JPN505.txt.data 187 466 24
## JPN506.txt.data 134 292 19
コーパスデータの中身を見る: texts()
•
ただし、そのまま実行すると、すべてのテキストが出力される。
•
各データが要素として入っているので、要素番号を指定することで個々のファイルデータを見ることができる。
texts(nicerJP.corpus)[3]
##
JPN503.txt.data
## "educational policy\nWhat do you think about \"yutori
kyouiku\"?\nIt is the
educational policy started about a decade ago.\nBecause
people had been educated based on learning as much knowledge as possible since
WWII and they become to luck an ability of thinking by themselves, Japanese
government started it to enable Japanese students to study objectively and acquire
the ability to live by themselves.\nNowadays, they
say this educational policy has much room to improve.\nIt
is obvious that as they could learn less knowledge than before, they become not
to be able to think and act objectively from the wide and deep prospect.\nSo I am for this critical argument generally.\nBut I think we should not see it as an entirely useless
and incorrect policy.\nThen, what should we do?\nI think it is important to analyze what points lead to
fail scientifically and acknowledge it precisely.\nFor
example, Shortening school time is said to be bad for students because they are playing
video games instead.\nIt is partially true, but when
it comes to the children from upper society, actually they get more time to
study effectively.\nUnless we argue this problem
deeply, we will fail to again."
KWIC検索: kwic(コーパスデータ, “検索文字列”)
kwic(nicerJP.corpus, "however")
##
## [JPN502.txt.data, 198]
a lot of fun. | However |
## [JPN506.txt.data, 166]
more important than love. | However |
## [JPN507.txt.data, 263]
story in the book. | However |
## [JPN507.txt.data, 318]
I under stand it. | However |
## [JPN511.txt.data, 271]
pronounce the language well. | However |
## [JPN512.txt.data, 33]
get over their disadvantages. | However |
## [JPN512.txt.data, 398]
? The answer is, | however |
文書行列(document-feature matrix)の作成: dfm()
•
行と列で、テキストごとに単語一覧を作成
–
行に、文書名(テキストファイル名)
– 列に、単語が並ぶ
•
どの文書にどの単語が入っているかを統一的に操作(分析)できる
•
対象は、コーパスデータ
• オプション
– stem化: stem=T
•
語尾変化をなくし「辞書形」にする(機械的にカットするので時々間違える?)
– 句読点の削除:remove_punct=T
– 機能語などの頻出語(stopwords)を除く:remove=stopwords(“english”)
nicerJP.dfm <- dfm(nicerJP.corpus,
stem=T, remove_punct=T)
nicerJP.dfm
##
Document-feature matrix of: 381 documents, 3,181 features (96.3% sparse).
##
features
## docs
what kind of sport do you like soccer base ball
## JPN501.txt.data 1 1 3 6 2
19 2 2 1 1
## JPN502.txt.data 3 0 7 0 1 2 0 0 0 0
## JPN503.txt.data 3 0 1 0 2 1 0 0 1 0
## JPN504.txt.data 0 0 3 17 4
13 0 0 0 0
## JPN505.txt.data 0 0 8 17 13 5 2 1 0 0
## JPN506.txt.data 1 0 3 0 3
14 0 0 0 0
## [ reached max_ndoc
... 375 more documents, reached max_nfeat ... 3,171
more features ]
文書行列の概要を見る:summary()
summary(nicerJP.dfm)
## Length Class Mode
## 1211961 dfm S4
文書行列の閲覧:View()
• Vが大文字なのに注意
View(nicerJP.dfm)
単語頻度一覧: topfeatures()
•
オプションで数字を付けて、何位まで出すか指定できる
topfeatures(nicerJP.dfm)
## to i the and is in of a sport it
## 3635 3098 2997 2465 2428 2197 2012 1474 1379 1336
Word Cloudの作成:textplot_wordcloud()
textplot_wordcloud(nicerJP.dfm)
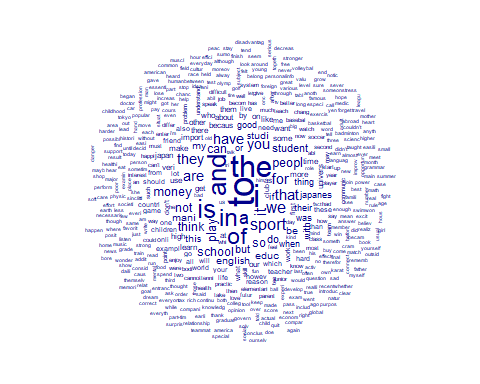
•
機能語が多くなるので、stopwordを除いたもので作った方が内容がよくわかる
いくつかの単語をまとめてグループにし、そのグループに該当するものの頻度を調べる。
例えば、接続語句のリストのグループを複数作っておいて、それぞれのグループに属する接続語句の頻度をかぞえる。
• グループを「辞書」と呼ぶ。コマンド名は dictionary()
• 対象はコーパスデータ
connectives
<- dictionary(list(additive = c("moreover", "further", "furthermore"),
adversative = c("however","nevertheless","conversely"),
resultative = c("therefore", "thus", "consequently")))
connectives.dfm <- dfm(nicerJP.corpus, dictionary = connectives)
View(connectives.dfm)
連語の頻度と結びつきの強さ:textstat_collocations(コーパスデータ)
textstat_collocations(nicerJP.corpus)
##
collocation count count_nested length
lambda
## 1
it is 532
0
2 3.8697744146
## 2
i think 467
0 2 3.9492608818
## 3
there are 261
0
2 5.4613400773
## 4
high school 287
0
2 6.7114116725
## 5
when
i
223
0 2 3.8942314348
## 6
if you 177
0
2 4.1491800073
オプション
•
連語の長さ(グラム数)の指定オプション: size = 数字
• 頻度の最低回数の指定オプション: min_count = 回数
3-gramで、最低限100回以上出現するもの
textstat_collocations(nicerJP.corpus, size = 3, min_count = 100)
##
collocation count count_nested length lambda
z
## 1
when i was 109
0 3 0.8053472 1.7087142
## 2
a lot of 262
0
3 0.6460580 0.3836656
## 3 junior high school 121
0 3 -1.2020138
-0.8044396
## 4 i think that
148
0 3
-0.6168513 -2.9437477
## 5
i want to 107
0 3
-0.9432875 -3.4151049
連語表現の検索
具体的な連語をベクトルにまとめておく
multiword <- c("in addition", "on the other hand", "as a result")
「フレーズ」という単位で扱われるように指定する
rengo <- phrase(multiword)
kwic検索
kwic(nicerJP.corpus, rengo)
##
## [JPN504.txt.data, 100:102]
and jumping to win. |
## [JPN506.txt.data,
72:73]
is necessarily to live. |
## [JPN510.txt.data, 116:119]
and called it education. |
## [JPN511.txt.data, 102:103]
this is most prominent. |
## [JPN512.txt.data, 286:289]
student of the class. |
## [JPN514.txt.data,
52:55]
as early as possible. |
##
## As a result | , their body become
more
## In addition | to these things, you
## On the other hand | when they work in
their
## In addition | that, English is easy
## On the other hand | , those who have
slight
## On the other hand | , others think we
should
rengo.df <- kwic(nicerJP.corpus,
rengo)
write.table(rengo.df, "rengo.df.txt")